At least I believe it is a tit but of which kind?

(click to view in full size)
edit: Solved, no Tit but a Nuthatch. /edit
At least I believe it is a tit but of which kind?
(click to view in full size)
edit: Solved, no Tit but a Nuthatch. /edit
… so that we have a chance to reproduce it.

In the end of the day, developers can only fix bugs they can analyze or see. This is especially valid for video bugs.
If you encounter a video bug, like e.g. video flickers, shows green or purple blotches, does not play at all, shows an error message, please fill out the https://vivaldi.com/bugreport/ form in the following way:
Affected product *: select Vivaldi browser
Type of issue *: select Problem / Defect
Summary *: This is a misnomer, it is actually the headline we see in the Bugtracker and the space is limited. A short description in one sentence. Please don’t try to make the sentence longer than absolutely needed, because everything that is too long gets cut off.
Example of a good Summary
Video on Youtube shows purple stripes / freezes / shows error message
Example of not really helpful summary
Lately, when I was visiting my grandmother and we wanted to watch videos on her Vivaldi, while the cat was sleeping on the sofa, I saw that sometimes (I hope you get the point by now, and yes, we have got such bug reports in the past)
URL where it occurred, if relevant: This is a crucial info, when it comes to video bugs. Enter the exact url to one page where the bug happens and where it always happens for you.
Example of an exact URL
https://www.youtube.com/watch?v=feGKcVUjj0s
Examples of unusable URLs
because those sites play videos for us just fine. We can not visit all pages of e.g. Youtube to find all of the videos that don’t work, our lifespan is not long enough for that.
https://www.youtube.com/ twitter.com https://www.facebook.com twitch.tv
You can add other exact urls in the following field:
Describe in steps how to reproduce the bug: This is the most important part. Here goes all of the information for how to trigger the bug. Split it into small chunks that we can follow step by step. Please include the video settings. Additional info goes here too. Try to format it like this and please include the dashes in front of the steps:
- open https://www.youtube.com/watch?v=feGKcVUjj0s - switch to 1080p / 60 Hz (important because the site might deliver different formats on different resolutions) - click on the fullscreen button in the video - stop the video - leave fullscreen again ---- GPU: Nvidia 1060 (important!) Driver version: (if you know it) ---- Does it work in older versions of Vivaldi or other browsers? (list here) ---- Settings you have changed in the browser (like hardware acceleration) blocking extensions you use (like uBlock) audio and video related extensions you use
If you can, try to confirm if it works with a clean profile or with the latest Snapshot. You can install it in parallel to your regular install as a Stand alone Version of Vivaldi to avoid clashes.
What did you expect to happen *: Here goes the description what should have happened when you performed the steps:
- the page should open - the video goes to fullscreen - the video should stop - the video returns to normal view
What had actually happened *: Well …
After stopping the video and leaving fullscreen the video showed purple stripes
Apart from the Email (Only used if we need to ask for info regarding this bug) * and answering the security question at the end of the form you don’t need to change the other fields if you report the bug with the Vivaldi Browser where the bug occurred, otherwise be as exact as you can.
The email address should be valid if you want to receive the automatic confirmation mail from the bug tracking system, which includes the VB-#### number. You can reply to that mail and even send attachments with additional info (if needed), some of it being the following:
Info about your video settings and GPU
vivaldi://gpu into the address-bar and hit EnterIn case of a browser or tab crash (dead bird, black or gray screen)
vivaldi://about/ into the address-bar and press EnterUser Data folder should be a folder named crashpadSome additional info in case of extensions (optional, if not too much, you can copy it into the Steps field)
vivaldi://system/ into the address-bar and hit EnterThank You for reading through all of this! It might sound complicated and tedious, but it helps us a lot to analyze what went wrong – and we can only fix bugs we can analyze.
Thank You for your time and using Vivaldi!
(Title photo by Chris Murray on Unsplash, cropped to fit here)
134 lines of code, 4 normal functions, 20 calls to chrome.something APIs, some of them nested, 0 const, 0 let, 0 var, 0 ESLint errors, 0 Vivaldi debugger errors.
5h wasted with refactoring and debugging because I wanted to make it run, but it didn’t want to work as I wanted and I thought I am an idiot – until I cross checked in naked Chromium.
Result: I am not an idiot.
There are at least 4 BUGS in Vivaldi’s implementation of multiple browser windows, extensions buttons and history display handling.
This is no fun.
… while painting the Mona Lisa, the Jesus portrait and his self-portrait, sat in front of his mirror while portraying himself, silently smiling about the generations to come who try to interpret the images …

… but probably I am totally wrong with that.
… so I had to cheat.

I imported a photo as backdrop image in Harmony Keymod (Site closed. Grab it from archive.org and clean up all the code added by archive org), then set the brush to “shaded”, the “offset-scale” to about 80 (I reeally need a better name for that), and started following the contours or shadows with long continuous strokes. To avoid interactions between the strokes I occasionally pressed the “B” key to break the relationship between the strokes. The occasional “U” key (undo! How could we only live without that in the dark ages) was of course involved too.
The image was drawn with a trackball, which is definitely not the best thing to use for drawing. A real artist with a tablet and a pen would have done it much better, especially the face, but I am quite content with the result.
Harmony was originally written by Ricardo “mrdoob” Cabello, I only did some heavy modifications to the code, see help in the application.
You can download the whole application by clicking on the
V-Menu > File > “save as…”: “Webpage, Complete”.
It is perfectly self-contained and works locally if you open the stored HTML file in Vivaldi. It does not need any server and stores no data on the server if you use the online version.
PS: There is a chromium bug which causes a massive RAM explosion with one of the Javascript commands I used for undo and redo on some hardware – see https://bugs.chromium.org/p/chromium/issues/detail?id=242215 – which hits Vivaldi too in combination with some hardware. If you did overwrite chrome://flags/#ignore-gpu-blacklist please consider to disable the overwrite. If you didn’t overwrite it and are still hit by it, you sadly have to wait until the chromium authors have fixed the bug.
![]()
(right click on the image and open in a new tab to see it in its full glory)
All what should become a great mess later started with a single bug report some time back:

(dramatic music effect)
found by Gwendragon, who in the following events tested, logged and categorized a lot of audio stuff too.
This bug happened only on a single site, which is well frequented in one country, but otherwise rather irrelevant.
Back then we could only check if it works for us – which it did for those who tested it after spoofing the user agent – so this bug was set to “cannot reproduce” (which means: Closed) after contacting the site owner because at that time it appeared to be a problem for the site to fix.
Usually this is the end of the story, the developers can only fix what they see and what they can analyze, and if it works for the testers and the developers, it can’t be broken, right?
Sadly not.
Somehow we managed to forget one operating system (OS) during the check, which was partly my fault, because usually I use that OS while testing.
All was good until the next report came in for exactly the same site. We checked it again (usual procedure, no bug gets closed unchecked), this time with the right OS too and the result was: [insert some heavy cussing and swearing here – be creative, ’cause I was]!
Not only that – suddenly reports about dozens of other sites started popping up!
Well, no panic, but no real solution in sight either, which is quite frustrating because at that time all of the developers, who can fix this kind of bugs, were heavily burdened with really important stuff like frozen UI or crashes, which of course have a higher priority, especially because super traffic-heavy sites like YT, Vimeo etc. worked well – but of course those audio bugs were constantly nagging in the background.
Then, one day, it was finally possible to assign a developer to the problem, but the fix was everything but easy.
One of the first things was to find out where it breaks and what exactly breaks – which sounds easy enough but isn’t, especially if you have to deal with the codecs inside of the OS because prohibitive license fees from the MPEG-LA and the Fraunhofer institute forbid to bundle the full ffmpeg+aac codec in binary form to Vivaldi, no thanks to them.
(Linux users might have noticed by now, that they are not hit by this because they can steal re-purpose the original Chrome codecs hosted in the usual repositories – a luxury the owners of other OSs don’t have)
The first thing to do was to add some sophisticated debugging code to the internal builds which can provide log files for the sites that were affected by the issue.
Said and done, we testers (both the employed and we volunteers) went through all of the bugs and created tons of big log files which we dumped on the poor Developer. After some time some of us became experienced enough to identify some common problems so that we could “Duplicate” bugs (meaning link together bugs that have the identical cause) on some kind of master bugs (usually the bug where the exact problem was first seen).
One thing all of those bugs had in common was the interaction between Vivaldi and the OS codecs. First Vivaldi needed to parse out the correct information from the media stream to get the correct settings for the audio decoder, then it needed to deliver it to the OS in exactly the right way or everything would break, which it still did at that time. This meant digging deep into the OS – one of the developers even went so far to read through The Windows Bible (a set of 1k+ page books that describe the internal workings in detail) to find “the right MS way(TM)” to do that.
This resulted in the first set of patches, or, to be more precise: One single patch which fixed a lot of the problems that existed.
(Here my part of hero worshiping: Patricia did this patch “blind” – i.e. without working on the OS directly! And it worked on the first try! That is quite a huge feat!)
… because this fixed only the most visible bugs, or audible, in this case.
There was a different bunch of similar bugs – which audibly sounded the same but internally weren’t – we saw that they were there but at that point we could not set see what exactly caused it, so back to writing log files, but this time with the improved “media bug logger 3000(TM)” to get even more data and again we dumped it on the developer: Set me on the watch-list for ALL of those bugs!
(slightly misquoted, but that was the essence of what Patricia said)
Those bugs were related with the way the servers send the data. To get a grip on those, the log files alone were not enough, because they told us only what the browser thinks it has seen – which might not be and was not always the same as is really there.
Side note: To understand that one must know that the involved AAC files can be delivered in multiple ways: With different profiles, with the profile announcing what is inside (the easier case), some with implicit announcement (which means we need to look inside of the data), some without any headers at all and some of those even encrypted (more about those later).
We had to find a way to get the raw “files” as delivered by the server. Sadly they are not delivered as files, but in little chunks that temporarily exist in the RAM. Downloading the requested data with the dev tools was no option1, so Tarquin came up with the genius idea to grab the stuff with an extension (no, even that will not give you a working file, don’t bother to ask for a downloader. I can hear your thoughts from here, the extension doesn’t work that way 😜 ) and finally we were able to “download” small bunches of the raw data, but when we tried to look into those, a lot of what was inside looked like a garbled mess. We are no audio decoding experts, usually the codecs “just do it” and we all hope they do it right, so we definitely needed to wise up, quick.
At some point, when I got totally frustrated about that pile of horse manure some servers delivered, I remembered that I have a friend who “is into that codec stuff”. Usually SagaraS works with video codecs and does all kinds of fancy things with them to improve the output quality but hey, it was worth a shot. So I dumped some of the grabbed files we couldn’t analyze at that point on him and asked him to find out what all of that stuff means. It took him some hours or so to get a grip on the audio stuff. When he tried to explain to me what it does and how we can analyze it – in purest AV Geek language 2, it could have been Swahili and I couldn’t have told the difference – my mind boggled. In the end we set up a teamviewer session the next day so that I could look over his shoulder while he showed me what to watch out for and how to do it. It wasn’t that easy, he is armed with an Hex Editor and knows how to use it, but he gave us the necessary clues. Additionally he pointed us to tools we can use to analyze that stuff, which was of great help too.
So back to logging and grabbing and analyzing it was, while the developers started fixing the next bunch of issues, this time in a teamed effort between Patricia and Julien because of the sheer amount, resulting in what you now know as More HTML5 audio fixes – Vivaldi Browser snapshot 1.15.1147.23.
Some web pages strictly resisted to give us meaningful content to grab with the above mentioned extension: All we got was seriously garbled junk.
In the end we had to dive deep into the code of the website player – cough, not really “we”, the developer of the extension. I could only confirm from the code (which was a PITA of its own: >60k lines of JavaScript is a lot to look through) that they encrypt the stuff on the server and decrypt it in the browser on the fly and dynamically add the header to it, but not what it exactly does. Finally the Tarquin found the exact place where to grab the necessary information needed for the decryption module, so be prepared for the next bunch of fixes.
Oh, btw: While doing all of that he wrote a gigantic test suite for all kinds of audio issues with several hundred tests. Yes, Vivaldi still fails some of them (but so do other browsers too, interestingly not all on the same tests) but it is still a work in progress, so stay tuned and watch the snapshot blog and the team blog 🙂
Original: VPNs, proxies and privacy. (translation draft)
In unserer Serie über Datenschutz und Sicherheit befassen wir uns mit echten VPNs, sicheren und anonymisierenden Web-Proxies, Browser-VPNs und erklären, worauf Sie bei einem VPN-Service achten müssen.
TEAMBOLG BLOG
Veröffentlicht am 17.04.2018 von Tarquin Wilton-Jones
—- Cover Bild —-
Normalerweise wird eine Verbindung zwischen Ihrem Browser und einer Website von Ihrem Browser zu Ihrem Computer, von Ihrem Computer zu Ihrem WiFi oder Heimnetzwerk (falls vorhanden), von Ihrem Heimnetzwerk zu Ihrem Internet Service Provider (ISP), von Ihrem ISP zu den nationalen Internet-Betreibern Ihres Landes, von den nationalen Internet-Betreibern Ihres Landes zu den nationalen Internet-Betreibern der Website, von den nationalen Internet-Betreibern des Landes der Website zu den Hosting-Providern der Website übertragen.
Das sind viele Schritte! In der Tat, der Verkehr kann auch auf dem Weg über andere Länder laufen, je nachdem, wo in der Welt Sie und die Website sich befinden.
Bei einer unsicheren Verbindung kann jeder, der einen Teil dieser Verbindung kontrolliert oder teilt, die Daten sehen, die über die Verbindung gesendet wurden – sei es jemand anderes auf Ihrem Computer, Ihrem Netzwerk, Ihrem ISP, den Betreibern der verschiedenen Bereiche des Internets unterwegs, Ihrer Regierung und den Regierungen aller Länder unterwegs, dem Hosting-Provider oder jedem anderen, der eine Website auf demselben Host besitzt.
Es ist alles sichtbar.
Wenn eine Website eine sichere Verbindung anbietet (HTTPS-URLs mit gültigen Zertifikaten und hochwertiger Verschlüsselung) und Sie diese nutzen, können die über die Verbindung gesendeten Daten nur von Ihrem Browser und der Website eingesehen werden.
Moment, ist es wirklich so einfach?
Nicht wirklich. Um die Verbindung herzustellen, muss der Browser die IP-Adresse der Website über einen DNS-Dienst abfragen, der normalerweise von Ihrem ISP bereitgestellt wird. Er verwendet dann diese IP-Adresse, um die Verbindung herzustellen. Das bedeutet, dass jeder, der die Verbindung überwacht, die Domain der Website in einer DNS-Anfrage sieht und somit herausfinden kann, zu welcher Website Sie Verbindung aufnehmen, selbst wenn er nicht sehen kann, was gesendet wird.
Selbst wenn Sie in der Lage sind, einen sicheren DNS-Dienst zu verwenden, kann jeder, der die Verbindung überwacht, sehen, mit welcher IP-Adresse er verbunden ist und mit einem Reverse-DNS-Lookup herausfinden, welche Website Sie besuchen.
Wenn Leute ein VPN zum Browsen benutzen, ist es normalerweise, weil sie eines von zwei sehr unterschiedlichen Dingen tun wollen:
— BILD 1 —
In ihrer reinsten Form bieten VPNs eine Möglichkeit, Ihren Computer sicher mit einem anderen Netzwerk zu verbinden, z. B. dem Arbeitsnetzwerk Ihres Arbeitgebers. Wenn Ihr Computer versucht, Daten über das Netzwerk zu senden, verschlüsselt ein VPN-Dienst auf Ihrem Computer die Daten und sendet sie über das Internet an den Ziel-VPN-Server, der sich in dem Netzwerk befindet, mit dem Sie sich verbinden möchten. Es entschlüsselt den Netzwerkverkehr und sendet ihn über das Zielnetzwerk, als ob Ihr Computer es selbst getan hätte. Die Antworten aus dem Netzwerk werden auf die gleiche Weise an Ihren Computer zurückgesendet.
Jeder, der einen anderen Teil der Verbindung auf dem Weg überwacht, kann nicht sehen, was gesendet wurde oder mit welchem Computer im Zielnetzwerk Ihr Computer verbunden war.
Klingt gut, aber ist es das, was die meisten VPN-Dienste tatsächlich tun? Die Antwort ist “Nein”. Hier kommen die Proxies ins Spiel.
Ein Proxy ist ein Dienst, der Anfragen an Websites im Namen Ihres Computers stellt. Der Browser ist so eingestellt, dass er sich über den Proxy verbindet. Wenn der Browser beginnt, eine Website zu laden, verbindet er sich mit dem Proxy auf die gleiche grundlegende Weise, wie er sich mit einer Website verbinden würde, und stellt seine Anfrage. Der Proxy stellt dann die Anfrage an die Website im Namen des Browsers, und wenn die Website antwortet, sendet er die Antwort an den Browser zurück.
Dies mag den Vorteil bieten, dass die Website Ihre IP-Adresse nicht sehen kann (was die zweite Gruppe von Nutzern anspricht), aber ein normaler Proxy wird Ihre IP-Adresse über den X-Forwarded-For-Header an die Website senden. Schließlich wollen die Proxy-Besitzer nicht beschuldigt werden, wenn Sie versuchen, eine Website anzugreifen – so wissen die Website-Besitzer, dass es sich tatsächlich um einen Angriff von Ihrer IP-Adresse handelt.
Natürlich können Sie auch versuchen, einen gefälschten X-Forwarded-For-Header zu Ihren Anfragen hinzuzufügen, um zu versuchen, jemand anderem die Schuld zuzuweisen, aber Websites können eine Liste bekannter und vertrauenswürdiger Proxy-Adressen verwenden, um festzustellen, ob Ihr X-Forwarded-For-Header möglicherweise gefälscht ist.
Die meisten Proxies, so genannte HTTPS-Proxies, können ebenfalls sichere Verbindungen direkt an die Website weiterleiten, da sie diese ohne die Zertifikate der Website nicht entschlüsseln können. Dies ermöglicht die Nutzung von HTTPS-Websites über einen Proxy.
Ein Proxy kann auch versuchen, die Verbindung zu entschlüsseln, aber dazu muss er dem Browser ein falsches Zertifikat – sein eigenes Root-Zertifikat – vorlegen, das der Browser als nicht vertrauenswürdig erkennt und deshalb eine Fehlermeldung anzeigt, um Sie vor dem Abfangen zu schützen. Dies wird manchmal zum Debuggen von Websites verwendet. Dabei muss die Person, die den Test durchführt, das Zertifikat des Proxys akzeptieren. Dies wird manchmal auch von Antivirenprodukten durchgeführt, damit sie die Verbindung scannen können.
Sichere Web-Proxies ermöglichen eine sichere Verbindung zum Proxy, auch wenn die zu verbindende Website eine HTTP-Verbindung (oder eine unsichere HTTPS-Verbindung) verwendet. Dies hat den Vorteil, dass andere Benutzer Ihres lokalen Netzwerks die Netzwerkdaten nicht sehen können (was die erste Gruppe von Benutzern anspricht). Sie können sehen, dass Sie sich mit einem sicheren Web-Proxy verbinden (obwohl die Verbindung wirklich nur wie eine sichere Website-Verbindung aussieht), aber sie können nicht sehen, welche Daten über diese Verbindung gesendet werden. Natürlich kann die Website immer noch den X-Forwarded-For-Header sehen, so dass sie immer noch Ihre IP-Adresse kennt (unerwünscht für die zweite Gruppe von Benutzern).
Um vertrauenswürdig zu sein, verwendet ein sicherer Web-Proxy auch Zertifikate zum Nachweis seiner Identität, so dass Sie wissen können, dass Sie sich mit dem richtigen sicheren Web-Proxy verbinden – andernfalls könnte jemand Ihre Proxy-Verbindung abfangen und einen gefälschten sicheren Web-Proxy präsentieren, so dass er Ihre Verbindung zu ihm überwachen kann.
Ein anonymisierender Proxy ist im Grunde nur ein Proxy oder ein sicherer Web-Proxy, der den X-Forwarded-For-Header bei der Verbindung zu Webseiten nicht sendet. Dies bedeutet, dass die Website Ihre IP-Adresse nicht sehen kann, wodurch Sie für die Website anonym bleiben (was für die zweite Gruppe von Nutzern attraktiv ist).
Einige Dienste bieten auch die Möglichkeit, die Seite abzufangen, um JavaScript und andere unerwünschte Inhalte zu entfernen, aber das bedeutet, dass Sie auch den Proxy-Besitzer mit allen Anmeldungen versorgen müssen, und der Proxy-Besitzer kann sehen, was Sie tun, auch auf sicheren Websites. Es tauscht nur ein Datenschutzrisiko gegen ein anderes aus.
Es scheint, dass ein anonymisierender sicherer Web-Proxy beide Fälle auf einmal lösen würde, aber es ist nicht so einfach, und es gibt viele andere Dinge zu beachten, z.B. wie Ihr Netzwerk und Ihr Computer eingerichtet sind. Ihr Computer kann auch DNS-Anfragen senden, wenn Sie eine Verbindung zu einer Website herstellen, CRL- und OCSP-Anfragen, wenn Sie Website-Zertifikate verwenden (wenn CRLSet nicht verfügbar ist), und der Browser kann auch andere Anfragen senden, z. B. Anfragen zum Schutz vor Malware oder Miniaturansichten. Hier kann ein VPN besser sein (aber es ist wichtig zu beachten, dass die meisten es nicht sind).
Es bedeutet auch, dass der Proxy-Dienst die Schuld zugewiesen bekommt, wenn ein Benutzer den Proxy benutzt, um einen Angriff zu starten. Um dies zu vermeiden, können die Proxy-Besitzer Verbindungen drosseln oder Logins verlangen und Protokolle der Verbindungen führen, so dass die richtige Person zur Verantwortung gezogen werden kann. Dies widerspricht dem Zweck für jeden, der versucht, den Proxy zum Schutz der Privatsphäre zu nutzen.
In den meisten Fällen sind VPN-Dienste nichts anderes als ein anonymisierender, sicherer Web-Proxy mit der Bezeichnung “VPN”. Sie behaupten oft, dass sie “sichere Website-Verbindungen” oder “Ihre Website-Verbindungen verschlüsseln”. Beides stimmt nicht, aber viele Unternehmen greifen auf solche Formulierungen zurück, um mit der Konkurrenz Schritt zu halten. Ein solcher VPN-Dienst kann unmöglich eine Verbindung zu einer Website sichern, da er nur einen Teil dieser Verbindung kontrolliert.
—- BILD 2 —-
Mit anderen Worten, das VPN wird nicht als reines VPN verwendet, sondern als Proxy. Während die Verbindung zwischen Ihrem Browser und dem VPN-Server sicher verläuft, muss er das Netzwerk des VPN-Servers verlassen und ins Internet zurückkehren, um eine Verbindung zur Website herzustellen. Die Verbindung zur Website ist genauso unsicher (oder sicher, wenn sie HTTPS verwendet) wie immer. Die Verbindung konnte in der zweiten Hälfte der Fahrt noch abgefangen werden. Alles, was das VPN in diesem Fall tun kann, ist, ein wenig Privatsphäre über einen Teil der Verbindung hinzuzufügen.
Wenn wir über VPNs sprechen, müssen wir uns dringend von der Verwendung von “Secure” verabschieden und über die Verbesserung der Privatsphäre sprechen, denn das ist es, was ein sicherer Web-Proxy oder VPN-as-a-Proxy tatsächlich tut.
Theoretisch müsste ein VPN-as-a-Proxy nicht anonymisiert sein, aber in der Praxis sind es fast alle.
Der größte Unterschied zwischen einem sicheren Web-Proxy und einem VPN-as-a-Proxy besteht darin, dass das VPN – bei Verwendung eines geeigneten VPN-Dienstes auf dem Computer – den gesamten relevanten Datenverkehr erfassen kann, nicht nur den vom Browser initiierten Datenverkehr. Ein VPN kann auch DNS, OCSP, CRL und jeden anderen vom Browser erzeugten Streuverkehr erfassen, der sich nicht auf die Verbindung zur Website selbst bezieht (z. B. Malware-Schutzprüfungen). In einigen Fällen kann der Browser die Anzahl dieser Anfragen reduzieren, wenn er einen sicheren Web-Proxy verwendet, z.B. wenn er eigene DNS-Anfragen stellt, aber es gibt immer noch Fälle, die nicht auf allen Systemen zuverlässig erfasst werden können. Daher ist ein VPN-as-a-Proxy besser als ein sicherer Web-Proxy, der vorgibt, ein VPN zu sein.
Darüber hinaus geht es bei sicheren (HTTPS) Verbindungen um viel mehr als nur um Verschlüsselung. Sie versichern auch, dass die Verbindung zu einer Website geht, die ein vertrauenswürdiges Zertifikat besitzt, das beweist, dass niemand die Verbindung abgefangen und eine gefälschte Kopie der Website vorgelegt hat. Ein VPN kann das nicht ändern, und es kann keine unsichere Verbindung in eine sichere Verbindung verwandeln. Ohne das Zertifikatshandling ist auch eine vollständig verschlüsselte Verbindung nicht sicher.
Wenn eine Browser-Anwendung eine Funktion oder eine Erweiterung anbietet, die behauptet, ein VPN zu sein, das nur für diese einzelne Anwendung funktioniert, ist es ein gutes Zeichen, dass es sich nicht um ein VPN, sondern um einen anonymisierenden sicheren Web-Proxy handelt. Das macht es nicht schlecht, es bedeutet nur, dass es wahrscheinlich Einschränkungen gibt, die es daran hindern, den gesamten Datenverkehr, der mit der Verbindung zusammenhängt, zu erfassen. Es kann keinen DNS-Verkehr erfassen (aber in einigen Fällen kann es, abhängig von der Implementierung). Es darf keine vom System durchgeführten Prüfungen zum Sperren von Zertifikaten erfassen. Das bedeutet, dass es zwar den größten Teil des Datenverkehrs verbergen kann, aber dennoch kleine Informationsbits an dem Proxy vorbeikommen können, und jemand, der den Netzwerkverkehr von Ihrem Computer aus überwacht, könnte immer noch in der Lage sein, herauszufinden, welche Websites Sie besuchen – eine wichtige Überlegung zum Datenschutz, wenn Sie zur ersten Gruppe von Benutzern gehören.
Ein VPN-as-a-Proxy ist in diesem Fall viel besser, da er den gesamten Datenverkehr vom Computer erfasst. Dies bedeutet, dass Sie nicht die gleiche Wahl haben; entweder der gesamte Datenverkehr aus allen Anwendungen läuft über das VPN, oder nichts. Sie können nicht nur den Datenverkehr einer einzelnen Anwendung über das VPN laufen lassen.
Jedoch können sowohl ein anonymisierender VPN-as-a-Proxy als auch ein anonymisierender sicherer Web-Proxies Ihre IP-Adresse effektiv vor der Website verstecken, so dass die zweite Gruppe von Benutzern gut abgedeckt werden kann.
Bleiben Sie dran für weitere Tipps in unserer Serie zum Thema Datenschutz und Sicherheit.
Original Artikel und Diskussion: VPNs, proxies and privacy.
Dies ist eine inoffizielle Übersetzung auf freiwilliger Basis und ist nicht autorisiert oder geprüft von dem Unternehmen Vivaldi. Alle in der Übersetzung eventuell enthaltenen Fehler sind meine eigenen. Falls Ihnen Fehler auffallen, schreiben Sie bitte einen Kommentar unter diesem Blog Post.
I got a bit spare time and once again added a small bit of functionality to the script: Flood fill – or maybe better known as “bucket” tool to most people. The basic function is in, it fills enclosed areas with the selected foreground color and and it can even fill semi-transparent, depending on the opacity setting in the menu. Sadly I still miss the tolerance settings for it, the code is in, but the UI is my old and well known problem. I need a design.
The same goes for Dynadraw, which can can have 4 settings – something like elasticity, weight, velocity and if the angle is fixed or not. The code is ready for that, but I have absolutely no clue how to integrate it into the UI without making it too complex to handle.
Still to be done:
Combining stringy, curvy and web to one brush. I did not yet check how compatible they are to each other, but I believe it should work in some way.
… and finally I could need some help:
I would really appreciate if someone who knows UI graphics stuff – meaning design – can help me with some mock-ups and ideas for a design rebuild. I am running out of space with the new settings I am planning.
A native English speaker who can help me to find better fitting words for the settings would be welcome too.
You can try out the little program on my web-page quhno.internetstrahlen.de or visit the previous Harmony Keymod blog entry here.
PS: The image above was “drawn” with this application while testing things. but I am still proud of it because it is up until today the most realistic cloud I ever managed to draw – and It took less than 5 minutes 😀
( I know it sucks, but as I wrote before, I am no artist at all 😛 )
PS: There is a chromium bug which causes a massive RAM explosion with one of the Javascript commands I used for undo and redo on some hardware – see https://bugs.chromium.org/p/chromium/issues/detail?id=242215 – which hits Vivaldi too in combination with some hardware. If you did overwrite chrome://flags/#ignore-gpu-blacklist please consider to disable the overwrite. If you didn’t overwrite it and are still hit by it, you sadly have to wait until the chromium authors have fixed the bug.
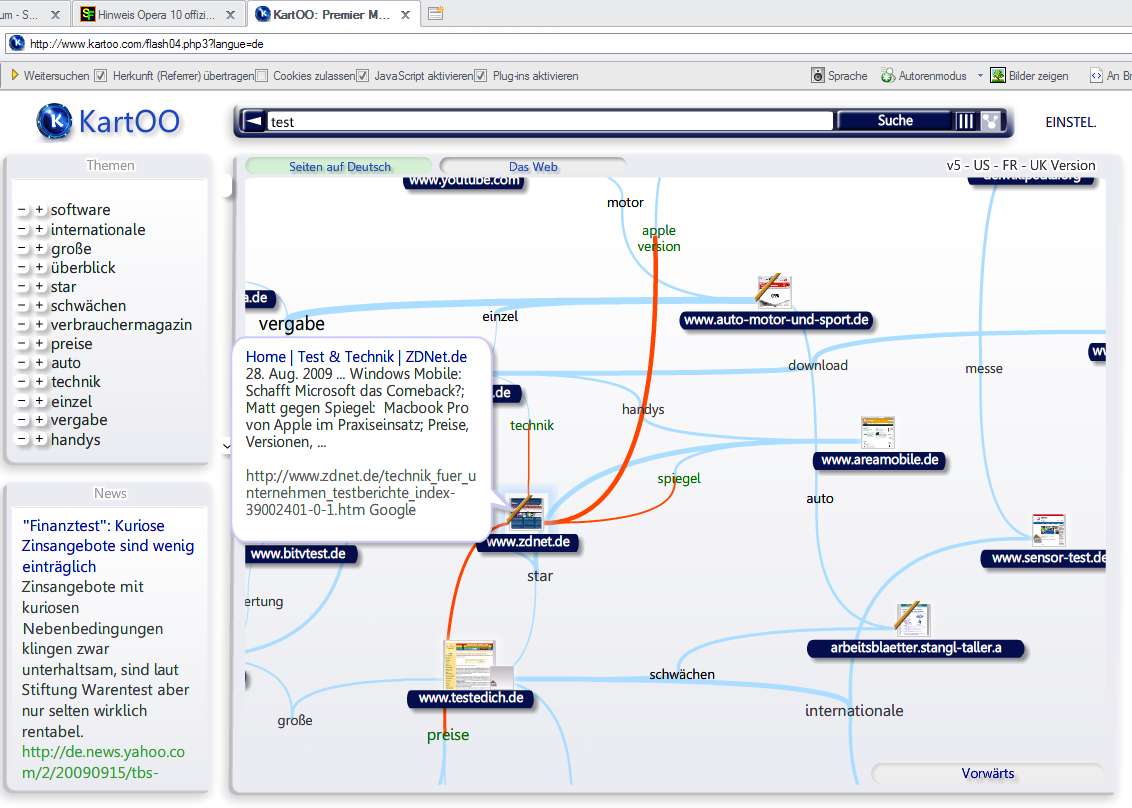
Whenever I knew what information I needed but didn’t know which search terms would lead me to this information, you were there and helped me reliably.
I only needed to enter a search term and you showed me a cloud of pictures with lines in between, showing the interlinks with added keywords connecting these pictures. You allowed to hover over one of the pictures to get a short summary of the content of the page.
I could click on one of the terms on the connecting lines and you provided me with a new, refined cloud until there were only 10 or 20 pages left, all of which were filled with very good results.
If I clicked on one of the preview pictures, you opened the page in a new tab in the browser and flagged that I have visited the page in your search window.
Also, it was possible to set which additional information I wanted to have and you even showed me groups of possible search results…
Unfortunately, you are no longer.
Why?
I have no idea.
Maybe you were just too innovative for the “I don’t have time” searchers who just want quick information tidbits, 1,000,000 hits in 0.23s, who are not interested in the quality of the results.
But maybe you were just too unknown and therefore didn’t get any advertising revenue – although I did a lot of advertising for you…
… but what’s a single voice against the overwhelming advertising power of the data kraken?
The above eulogy was originally posted February 12, 2010 on my.opera, it is still available in the Web Archive.
The first part of this article is a translated and slightly rewritten version – I am still moaning about its too early demise. I wonder if we will ever see a public search engine like this again.
Advertising money is what makes the web spin. Cases like the above, where new ideas and technologies were starved to death, maybe without noticing or maybe even deliberately, are still a thing, maybe even more than ever, as we can see with e.g. www.foundem.co.uk which is a vertical search engine. The technology and mathematics behind vertical search engines like those is really amazing, and they can solve problems the usual horizontal search engine suspects like Google, bing etc.pp. can’t, but have you ever heard about it? No? I guessed so …
The story behind it?
Read it in this New York Times Magazine article: The case against Google.
Also available in the waybackmachine. Make sure to press the stop button as soon as you see the article content to avoid the paywall redirection on the archived page.
Almost the same happened some years earlier to Cuil – which ironically was founded by some former Google employees.
Side note: Ignore the “criticism” part in the Wikipedia article – Cuil was still new and all new search engines I have ever seen had the same problems and much worse in their early days – yes, Google back then in 1997 too. Been there, seen that.
Not only did they have their own crawler that maintained a gigantic database of web pages, which at that time was about the same size as the ones of Google, Microsoft Search (now bing) and Altavista (while it was still a thing) combined, but beside the usual search result page they had a really interesting and working approach to make results actually digestible:
It was called “cpedia” but in opposition to the well known Wikipedia, it was based purely on their data mining agents which collected information all over the web and – now the really interesting part – wrote executive summaries (backed up with a links so that you could check the sources) in a length of about 1000 words, which were astonishingly well “written”, often almost indistinguishable to the work of a human author. If possible they backed up the results with meta data, such as statistics or analytic tools, linked to related videos or images too. This was a great way to get a cursory overview over almost everything you could imagine and sometimes even showed astonishing insights that were really hard to come by otherwise.
What happened to them?
Dead after a few rounds of fund raising and sold to Google (If you can’t squash them, buy them?) and because the advertising marked at that time was already taken over by Google, so this kind of business model was no longer viable.
