Back then …
Whenever I knew what information I needed but didn’t know which search terms would lead me to this information, you were there and helped me reliably.
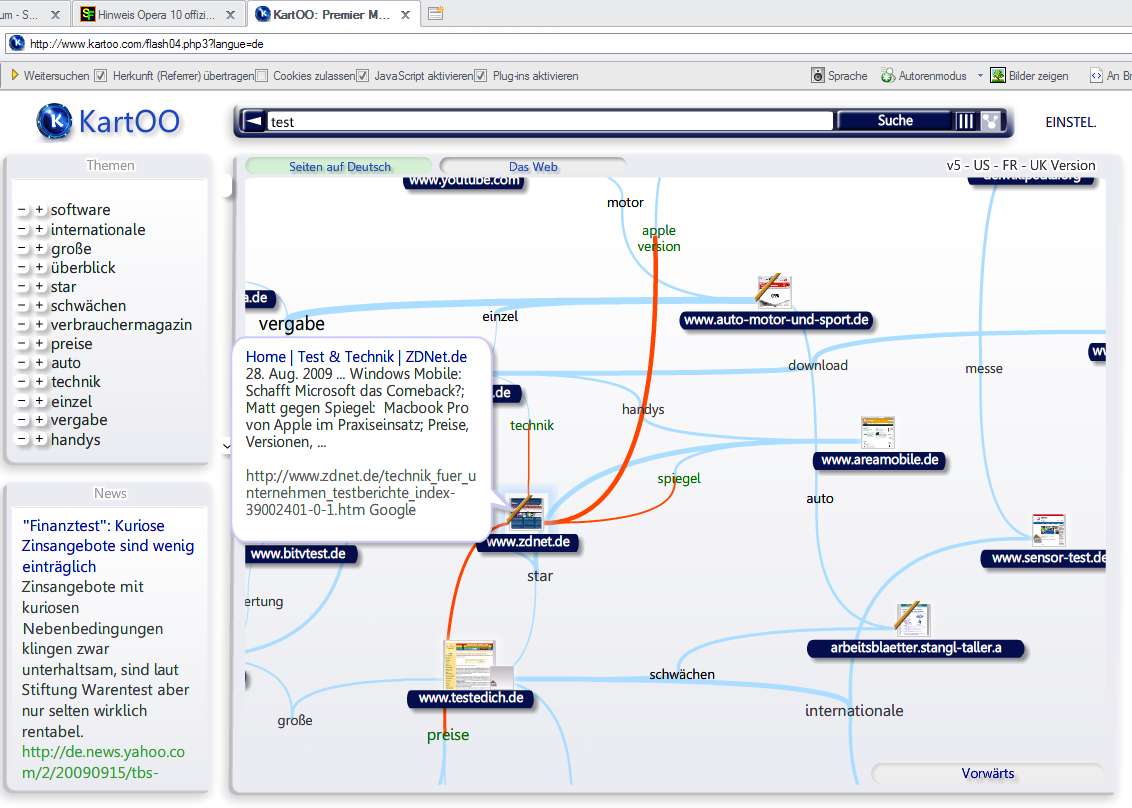
I only needed to enter a search term and you showed me a cloud of pictures with lines in between, showing the interlinks with added keywords connecting these pictures. You allowed to hover over one of the pictures to get a short summary of the content of the page.
I could click on one of the terms on the connecting lines and you provided me with a new, refined cloud until there were only 10 or 20 pages left, all of which were filled with very good results.
If I clicked on one of the preview pictures, you opened the page in a new tab in the browser and flagged that I have visited the page in your search window.
Also, it was possible to set which additional information I wanted to have and you even showed me groups of possible search results…
Unfortunately, you are no longer.
Why?
I have no idea.
Maybe you were just too innovative for the “I don’t have time” searchers who just want quick information tidbits, 1,000,000 hits in 0.23s, who are not interested in the quality of the results.
But maybe you were just too unknown and therefore didn’t get any advertising revenue – although I did a lot of advertising for you…
… but what’s a single voice against the overwhelming advertising power of the data kraken?
The above eulogy was originally posted February 12, 2010 on my.opera, it is still available in the Web Archive.
The first part of this article is a translated and slightly rewritten version – I am still moaning about its too early demise. I wonder if we will ever see a public search engine like this again.
… and today
Advertising money is what makes the web spin. Cases like the above, where new ideas and technologies were starved to death, maybe without noticing or maybe even deliberately, are still a thing, maybe even more than ever, as we can see with e.g. www.foundem.co.uk which is a vertical search engine. The technology and mathematics behind vertical search engines like those is really amazing, and they can solve problems the usual horizontal search engine suspects like Google, bing etc.pp. can’t, but have you ever heard about it? No? I guessed so …
The story behind it?
Read it in this New York Times Magazine article: The case against Google.
Also available in the waybackmachine. Make sure to press the stop button as soon as you see the article content to avoid the paywall redirection on the archived page.
Almost the same happened some years earlier to Cuil – which ironically was founded by some former Google employees.
Side note: Ignore the “criticism” part in the Wikipedia article – Cuil was still new and all new search engines I have ever seen had the same problems and much worse in their early days – yes, Google back then in 1997 too. Been there, seen that.
Not only did they have their own crawler that maintained a gigantic database of web pages, which at that time was about the same size as the ones of Google, Microsoft Search (now bing) and Altavista (while it was still a thing) combined, but beside the usual search result page they had a really interesting and working approach to make results actually digestible:
It was called “cpedia” but in opposition to the well known Wikipedia, it was based purely on their data mining agents which collected information all over the web and – now the really interesting part – wrote executive summaries (backed up with a links so that you could check the sources) in a length of about 1000 words, which were astonishingly well “written”, often almost indistinguishable to the work of a human author. If possible they backed up the results with meta data, such as statistics or analytic tools, linked to related videos or images too. This was a great way to get a cursory overview over almost everything you could imagine and sometimes even showed astonishing insights that were really hard to come by otherwise.
What happened to them?
Dead after a few rounds of fund raising and sold to Google (If you can’t squash them, buy them?) and because the advertising marked at that time was already taken over by Google, so this kind of business model was no longer viable.
great post thank you
I have been a heavy user of Kartoo search service from 2000 until its death, 2008 ? It was well designed and easy to use. Its graph approach deserves some recommandation. The links were very useful to understand connections between websites and sur faster.
Then, I switched to http://www.exalead.com and now to http://www.qwant.com
Vivaldi should consider Qwant as the default browser, or at least add it in the proposed list of default browsers. It is 100 % European search engine with shareholders in France and Germany.
Qwant is in my list of search engines too – right next to Ecosia – but both have the same problem: They are horizontal search engines, not vertical. So, if you don’t know how to search for a particular thing, finding it is highly unlikely.
(I am very good at searching, but not that good at finding 😀 )
Other than that: Yepp, some non US search engines would be nice and considering what is said about Qwant, that they spurt their own searchbot, it might sometimes give more meaningful results to “us Europeans” 🙂
PS: https://fr.wikipedia.org/wiki/KartOO “La société a été mise en liquidation judiciaire le 15 janvier 2010”
No love for the duck that goes searching? https://www.duckduckgo.com
There is a reason why DDG became a standard search engine in Vivaldi and I use it in combination with my other 30+ engines. The reasoning to include DDG was quite a different one than for Google, who are only in because “Google” became a verb that is impossible to ignore …
… but still: DDG is a “conventional” engine. Sometimes I need help finding things and search engines that can do that are really rare.
Maybe YIPPY is a viable alternative, at least it offers some semantic searching:
https://yippy.com/search/?v%3aproject=clusty-new&query=vivaldi
I’d still love to have some vertical search engine available.
Already in my list of “search engines” 😀
They are an aggregator/meta search engine and use the results of google, microsoft and possibly others. The basic technology behind it is the same or at least very similar to IBM Watson – really good for specific stuff which needs expert knowledge (sadly the real good stuff is only available for the paid business and enterprise accounts) and sometimes quite good for normal searches too.
One good thing: No tracking past the session.
Sounds much “Yahoo Pipes” which went the way of the Dodo without any notice. (Before Yahoo! became a four letter word.)
You could (Visually) build your own search from RSS feeds or site scraping. I had my own for VERY specific queries on some topics pertinent to myself and few others that I tried to gather and condense to then relay to that group.
There are some alternatives. See: https://www.makeuseof.com/tag/12-best-yahoo-pipes-alternatives-look/
But as many are on Git-Hub, and Git-Hub is now Microsoft…
Only visually – KartOO was a regular search engine which did it all by itself – you could help the search by selecting some categories but apart from that it was only a search engine.
Type search word (yes, one was best, you could type multiple but that made the search harder) then click on the interconnections between the result pages to refine the search in those directions. This does not sound like much and might misslead into believing that it is like the “related” pages search some other search engines offer, but it was much different because you could _see_ the interlinking words before you clicked on anything.
Sometimes I had the feeling they used some kind of an an additional reversed linking algorithm too – e.g. if you looked for “car” and added “green” you got interlinks *from* pages that pointed to green cars pages too, despite they by themselves did not have green cars in their content – but of course could point to other car pages too, which might lead to another page which points you to exactly what you are looking for, such building an association chain – I stop babbling now, you get the point.
Additionally they mapped out all interlinking keywords between sites which helped a lot to get where you wanted. Hard to describe but extremely helpful if you were looking for things you know existed somewhere but did not know how to find them – i.e. where traditional search engines utterly fail because they search only for things you have typed in and give you no real clues what else might be related to what you search. Standard “Suggestions” suck in 90% of all cases.
As I always say:
Searching is easy, everyone can search – finding is hard …
… especially if you need to search in a foreign language. 😉
There is again something named kartoo, http://www.kartoo.com/ but it is not the same – it is more a spiced-up directory search – well let’s use it for a while and try to find out how it works for my use case.