If you want to know what’s really inside of an extension, you can download the source code for chrome extensions via toolbar popup in .zip or .crx formats with the following extension Extension Source Downloader from mybrowseraddon.com
Author: quhno
Download Extensions from the Google webstore for offline inspection and install
We all know that Google does not get its act together and often times failed to detect, when Extensions contained malicious code – and that the culprits have become are very creative in evading the inspection bots. As happened multiple times in the past, […]
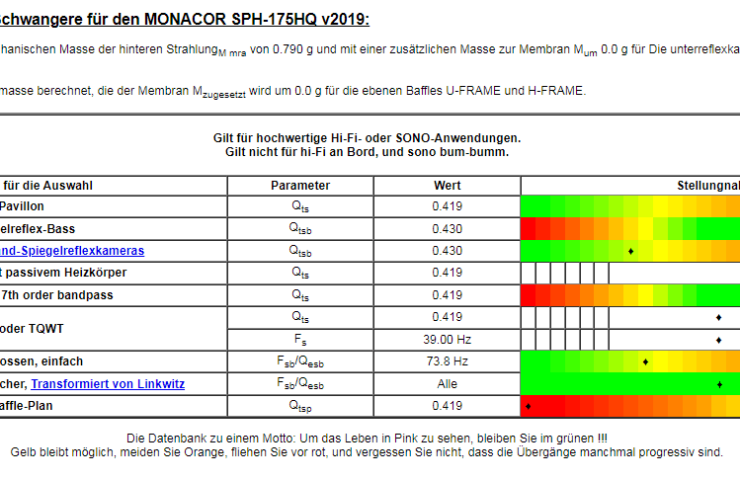
Pregnant With Passive Heater
full size image (opens in new tab) The translation tool Lingvanex, which is the one Vivaldi uses and hosts on its own servers in Iceland, translated this: That’s a good idea. Starring themes would allow for the creation of personal collections for sync and […]
Liquify aka IWarp arrived in Harmony
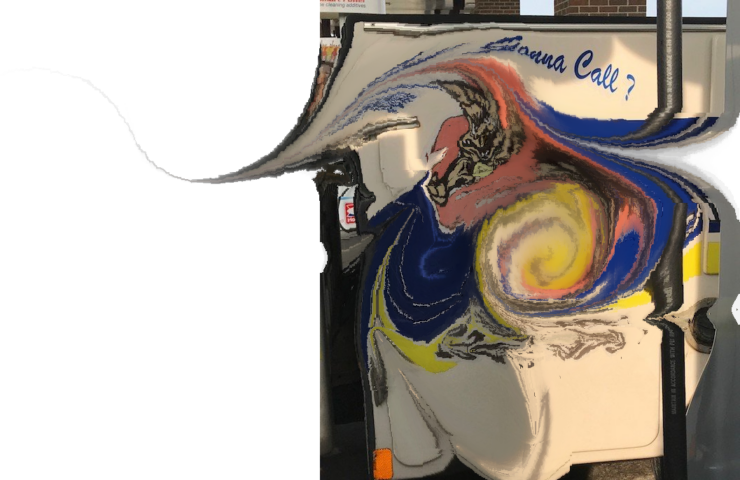
136 lines of additional vanilla JS code, plus some more lines for new UI elements and I have added my 32nd brush to Harmony, the procedural painting tool: Say hello to Liquify (PS), IWarp (GIMP) or however it is called in other full blown […]
Adding Search Engines to the Vivaldi Browser (followup)
Some search engines can’t be added to Vivaldi by right-click in the search field > “Add as Seach Engine …”, but only manually. The following describes a possible method to add some of those. If searches do not use a regular search field in […]
Discarding Problems in Vivaldi
While testing a new Vivaldi function (which is not yet in the public builds at the time of writing), I have found a serious bug (not a real bug, but more of a serious annoyance) in connection with my Auto Discard extension: The extension […]
After the Storm
Last time I was in Dortmund, a storm passed over the city and left this view in its wake …
Better Tab Stacking
Vivaldi’s tab stacks are a fiddly thing if you don’t use the window panel. Disadvantages of the existing tab stacking solution: If you have a large tab stack of maybe 60+ tabs, the tab previews can block the whole UI. (VB-17414) Especially in windowed […]
Simple and Boring
… is the title of a an article by Chris Coyer about managing complexity on websites and why simple & boring might get the job done where “fancy” might not. Head over to the article, it is well worth reading, and don’t forget to […]
First American exposed 885 MILLION full datasets. Translation of their statement to plain English
After exposing 885 MILLION full datasets title insurance records, including bank account numbers and statements, mortgage and tax records, Social Security numbers, wire transaction receipts, and drivers license images, which covers the last 16(!) years, the estate title insurance giant First American Financial Corp […]